Version 3.100.0
-
Seit der Version 3.100.0 wird in der App beim Versuche ein Gruppentreffen zu pflegen folgende mehrfach hintereinander erscheinende Meldungen angezeigt.
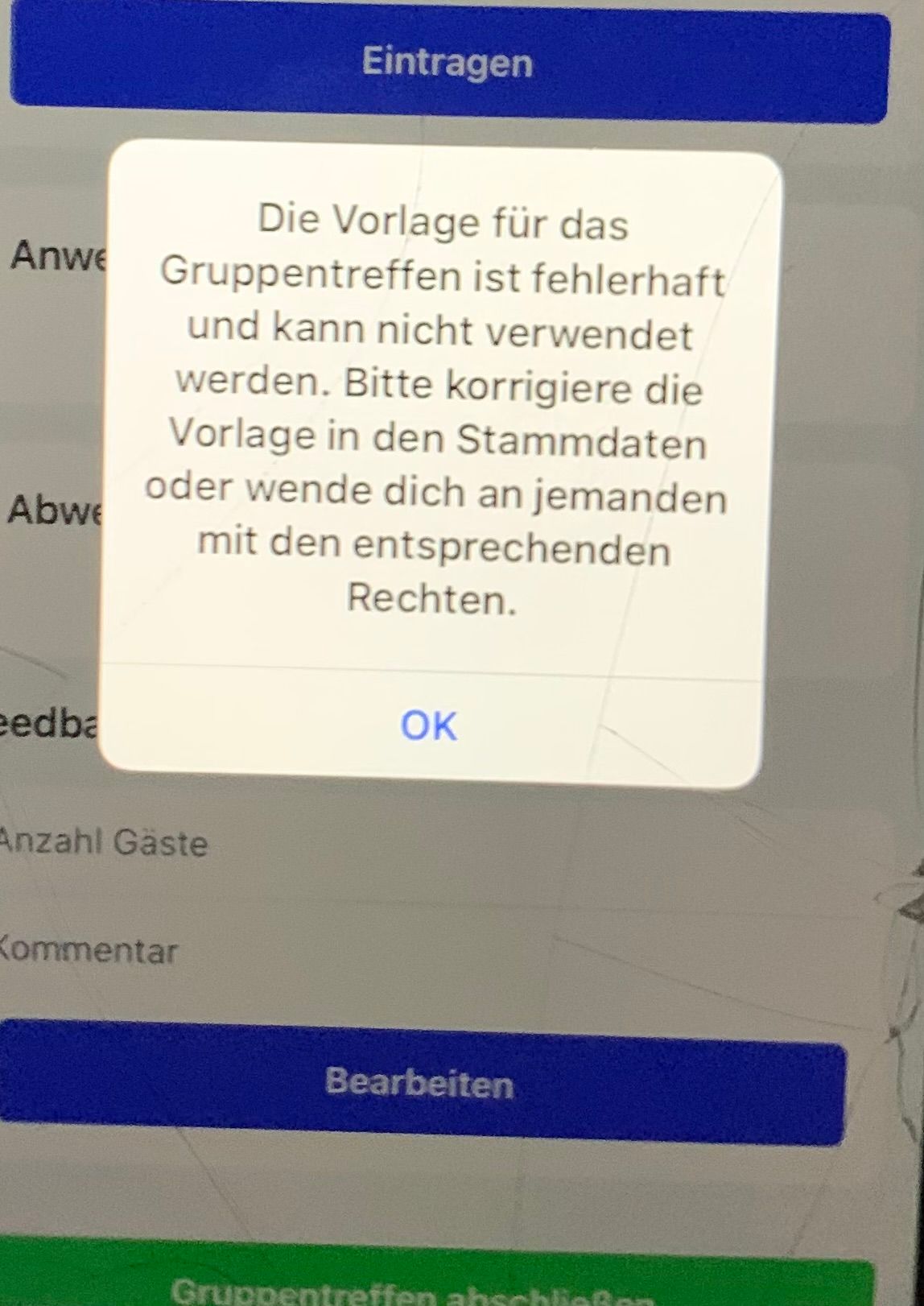
-
@hd Der Fehler ist uns bekannt und wird mit einer baldigen App Version behoben
-
@davidschilling
Seit der neuen Version lassen sich bei uns keine neuen Eventvorlagen mehr speichern.
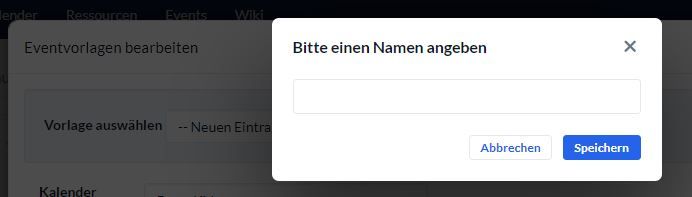
Das Namensfeld lässt sich nicht beschriften. -
@karin-d Welcher Browser wird benutzt?
-
Die Version ist jetzt auch für Self-Hoster live.
-
@davidschilling Ich benutze Firefox 115.0.2 (64-Bit)
-
@davidschilling Habe ich heute bemerkt. Eure API-"Verbesserungen" sind inkompatibel mit der aktuellen Version von
ctldap.
Hatte dort einen (vermutlich nicht beabsichtigten) Seiteneffekt benutzt, um die restriktiven, ineffizienten Pagination-Limits zu umgehen, indem ich "-1" als Limit übergeben habe. In der aktuellen Version führt das zu einem Crash der API:ErrorHandler: Doctrine\DBAL\Exception\SyntaxErrorException: An exception occurred while executing a query: SQLSTATE[42000]: Syntax error or access violation: 1064 You have an error in your SQL syntax; check the manual that corresponds to your MariaDB server version for the right syntax to use near '-1' at line 1; RequestId: 64b1e2cc2d4e5; Module: ; Param:Da wir ja Self-Hoster sind, konnte ich das mit einem bösen, illegalen fix im Code reparieren.
Könnt ihr bitte insystem/src/Api/ApiPaginator.php, Zeile31:
Das hier:
$this->limit = $limit;
bitte durch das hier ersetzen:
$this->limit = $limit < 1 ? PHP_INT_MAX : $limit;Die performanteste Alternative ist, die Anfrage
ctldap-seitig in viele parallele paginierte Anfragen zu zerlegen, was die Server-Last extrem nach oben treibt.
Ich glaube das wollt ihr nicht, besonders wenn wir demnächst zwangsweise in eure Cloud umziehen.")
-
@milux
-1war als Wert nie so gedacht und hat nur zufällig funktioniert. Für die nächste Version gibt es eine Validierung die überprüft, dass das Limit mindestens 1 ist.Warum wird denn überhaupt diese Api verwendet? Du hattest doch extra für den LDAP Wrapper damals die Funktionen
getGroupsDataundgetUsersDatahinzugefügt über die man die Personen und Gruppendaten sehr performant bekommt. -
@davidschilling Bist du dir sicher, dass ich diese Funktionen eingeführt habe? Kann sein, dass ich es inzwischen vergessen habe, ist ja schon verdammt lange her... aber ich dachte, die gab's schon?
Wie auch immer:
Da das nicht Teil der offiziellen, dokumentierten API ist, hielt ich es für sinnvoll, auf die offizielle API umzustellen, v. a. da ja demnächst alle in eure Cloud umziehen müssen.
Es hatte nicht zuletzt auch damit zu tun, dass man sie mittels Token ansprechen kann, was ich technisch für eleganter und intuitiver halte. Wenn das auch für diese Funktionen gehen sollte, dann Schande über mich, aber sie sind ja eben nicht offiziell dokumentiert...Bzgl. des Limits: Ich glaube, dass es eher die Regel als die Ausnahme ist, dass man sämtliche Daten abrufen möchte. Kannst du mir vielleicht erklären, was ihr euch von der Paginierung überhaupt erhofft? Ich sehe da nämlich aktuell nur Nachteile:
- Der Löwenanteil der Response-Time des Servers entfällt augenscheinlich auf Checks, die unabhängig von der Größe des Resultats sind. Ich hätte ähnliche Antwortzeiten auf unserem Server für 50, 100 oder 200 User, immer im dreistelligen ms-Bereich.
- Wenn ich nichts übersehen habe, wurde die Paginierung bisher in PHP umgesetzt, und jetzt neuerdings mit SQL LIMIT. Da wir aber immer noch von PHP sprechen, was zustandslos arbeitet, gehe ich mal naiv davon aus, dass die Anfragen nichts voneinander wissen. Heißt, wenn ich sekundenlange in Chunks User abfrage, und jemand fügt in der Zwischenzeit neue Datensätze in die DB ein, habe ich auch noch Lost Updates, korrekt?
- Und wenn der API-User unbedingt alle Datensätze auf einmal abfragen möchte, warum lässt man ihn dann nicht einfach? Er holt sie sich sowieso, nur eben viel langsamer und mit viel mehr Last auf dem Server, und evtl. unvollständig. Was soll das nützen?
Bei technisch sauber ausgeführter Paginierung muss man nach meinem Verständnis das Ergebnis puffern und einen Cursor darauf zur Verfügung stellen, mit dem man über die Ergebnis-View iterieren kann. Ich hab jetzt erklärt, warum euer bisheriger Ansatz das (wenn ich nichts übersehen habe) nicht leisten kann.
Aber vielleicht überzeugst du mich ja eines besseren, oder ich hab was übersehen.Sorry übrigens, wenn ich zu Anfang ein wenig salty eingestiegen bin, aber ich habe heute durch eure Optimierung schon wieder 2 Stunden Lebenszeit dabei verloren, raus zu finden, warum unsere NextCloud nicht mehr geht. Die hätte ich gerne anderweitig genutzt...
-
Ja, die Funktionen hattest du 2017 eingeführt
") Auch für diese kann der Logintoken verwendet werden. Allerdings sollte auch immer das Sessionhandling mitbenutzt werden.
Auch für diese kann der Logintoken verwendet werden. Allerdings sollte auch immer das Sessionhandling mitbenutzt werden.Warum man generell Paginierung nutzt kann man im Internet zu Hauf nachlesen, das müssen wir jetzt hier denke ich nicht groß diskutieren. Es ist ein Mechanismus um nicht immer alle Daten holen zu müssen, weil das potentiell sehr Rechenintensiv ist.
Gerade bei sehr großen Installationen kann das einen großen Unterschied machen.
Zum Thema Cursor: Man kann Paginierung unterschiedlich lösen. Mit Cursor oder mit Offset (https://stackoverflow.com/questions/55744926/offset-pagination-vs-cursor-pagination) bei uns macht das mit dem Cursor nicht viel Sinn, weil wir auch sortieren und davor auch alle Berechtigungen berechnen müssen und wir uns damit beim Cursor nicht wirklich was einsparen würden.
Die Paginierung machen wir in der Regel in der Datenbank. Das ist ziemlich performant.
Bei den Personen erlauben wir mittlerweile auch ein
limitvon 500, damit bekommt man auch bei größeren Installationen die Personen ohne allzuviele Requests.Allerdings würde ich dir aktuell empfehlen erstmal auf den Apis aufzubauen die du ursprünglich dafür gebaut hast, weil die viel performanter sind da sie nur für diesen Usecase ausgelegt sind.
Dass wir hier eine Änderung in der Api hatten die den LDAP Wrapper kaputt gemacht hat tut mir leid, auch wenn es auf eine nie unterstützte Funktion zurückzuführen ist.
-
@davidschilling Jetzt muss ich mal ganz dumm fragen:
Wenn die inoffizielle API von mir gut ist, was hält euch davon ab, sie auch über die dokumentierte, offizielle API für diesen Zweck verfügbar zu machen?Was die API angeht, werde ich vermutlich deinen Rat beherzigen und die Rolle rückwärts machen, allerdings weiterhin mit Token, s. nächster Absatz.Wenn du von Sessionhandling sprichst, meinst du höchstwahrscheinlich, dass weiterhin auch Cookies behalten werden sollen, oder?
Das macht es natürlich performanter, wenn ihr noch immer kompliziert berechnete ACLs o.ä. in der Session ablegen solltet, aber es macht die Abfrage-Logik viel komplizierter, da man hier im Gegensatz zum Token einen Login durchführen muss, wenn die Session abgelaufen ist. Ich würde es ehrlich vorziehen, eben diesen Kram nicht mehr machen zu müssen.
Aber jetzt frage ich nochmal ganz dumm: Wird denn bei einem Request via Token auch eine Session angelegt? Dann könnte ich das Cookie ja relativ unkompliziert mitschleifen, ohne mich direkt um die Session zu kümmern, oder? Das wäre ja tragbar.
Edit: Hab mir diese Frage schon selbst beantwortet. Cookies behalten hilft auch bei der offiziellen API, etwa 100 ms pro Request kann man auf unserem Server damit einsparen. Dürfte bei euch ähnlich sein.Zum Thema Paginierung:
Absolut richtig, ich denke über deren grundsätzliche Daseinsberechtigung wissen wir beide Bescheid. Aber die Kritik bezog sich auf ja speziell auf eure Umsetzung, und deine Erklärung bzgl. Offset vs. Cursor verstehe ich gar nicht. Der SO-Link beschreibt doch genau das: When querying static data, the performance cost alone may not be enough for you to use a cursor...
Wir könnten uns jetzt natürlich darüber streiten, ob User-Listen statische Daten sind, ich denke eher Nein. Aber gerade weil ihr vorher noch über den Daten Sortierungen und Berechnungen durchführt, würde doch ein Cursor-Ansatz Sinn ergeben, wenn man die Daten in Chunks bekommen möchte, oder reden wir gerade völlig aneinander vorbei?
Man müsste dann natürlich die Daten zwischenspeichern, z.B. in Redis, und dem User dann eine Art Cursor-Key zurückschicken, mit dem er dann die Daten stückweise abrufen kann. Aber gerade hier würde es doch total Sinn ergeben, weil man ja dann keine Berechtigungen mehr weiter prüfen muss, während der User im weiteren nur noch aus seinem Buffer liest, bis er "leer gelesen" ist oder ein Timeout auftritt.Und was meinst du damit, dass ihr die Paginierung in der DB macht? Beziehst du dich auf das LIMIT-Statement? Das ist auf jeden Fall sehr viel besser als PHP-Code, überhaupt keine Frage! Aber es ist halt noch immer Offset-basiert und somit fehlerhaft, wenn die Daten nicht statisch über alle semantisch zusammenhängenden Anfragen hinweg sind.
500 ist besser als nichts, aber gerade bei großen Installationen kommt man damit trotzdem nicht hin, daher frage ich jetzt nochmal, denn ich hab noch immer keine Antwort darauf bekommen: Warum lasst ihr die User nicht einfach so viele Datensätze abrufen, wie technisch sinnvoll möglich ist?
Ich kann ja nachvollziehen, dass man zwecks Server-Ressourcen irgendwo ein Limit setzen muss, aber bei eurer Hardware wären da doch eher 10 000 oder 100 000 Records sinnvoll, und nicht magere 500? -
@davidschilling sagte in Version 3.100.0:
Bei den Personen erlauben wir auch ein limit von 500
"mittlerweile" ist nicht Diese Version? bei uns steht:
Damit könnte ich auch als Nicht-Selfhoster ohne "bösen, illegalen fix im Code zu reparieren
 " viel besser leben.
" viel besser leben. -
@ralf-werner es geht um die API, nicht ums Frontend
-
-
@davidschilling Nachtrag bzgl. meiner API-Funktionen:
Ich habe heute
ctldapgepatcht und weiß jetzt wieder, warum ich "meine" Funktionen nicht weiter benutzen wollte.
Diese alte API erfordert den Einsatz eines CSRF-Protection-Tokens und Form-Feldern. Offensichtlich ist sie gar nicht als API für externe Tools gedacht, und das merkt man auch.
Ich habe sie nur deswegen genutzt, weil es damals noch keine REST-API gab, und ich entsprechend in den sauren Apfel beißen und das nehmen musste, was da war.
Dieses CSRF-Gedöns ist für nicht-Browser-Abrufe (die mit Token) nutzlos und macht, ebenso wie die damals notwendige Anmeldung ohne Token, den Ablauf unnötig komplex, fehleranfällig und langsam.Jetzt frage ich die REST-API mit parallelen Anfragen ab. Das geht ähnlich schnell - häufig sogar noch deutlich schneller - als meine alte Hack-Methode, weil ich die Anzahl der abgerufenen Seiten cache und nur im Bedarfsfall "nachfasse", wenn weitere Seiten dazukommen. In den meisten Fällen frage ich so immer genau die richtige Menge an Seiten parallel an.
Einziges Manko ist die höhere Last auf dem Server, wir brauchen für Personen und Gruppen z.B. jeweils jetzt 2 Requests statt einem, aber damit können wir gut leben. Richtig große Installationen werden euren Server natürlich so weit stärker belasten.Wie gesagt: Ich würde mich sehr freuen, wenn die relevanten Funktionen "meiner" API in eure offizielle REST-API wandern würden. Ohne die lästige Paginierung, versteht sich.
-
@milux Danke fürs fixen.
Das CSRF-Token holen wäre ein Api Request gewesen, der recht schnell geht. Das wäre vermutlich auch gegangen. Aber die jetzige Lösung sollte auch passen.
Wie viele parallele Abfragen laufen gleichzeitig? Gibt es dafür ein Limit?
Ich stimmt dir zu, dass so eine Api in der offiziellen Api gut wäre. Wann und ob ich dazu komme kann ich aber noch nicht sagen.
-
@davidschilling Gerne, wobei es mir natürlich lieber gewesen wäre, wenn ihr meinen Einzeiler übernommen hättet.
Was hält euch denn davon ab, die Grenzen auf ein technisch sinnvolles/vertretbares Maß anzuheben?
Es gibt sicher technisch irgendwelche Limits, aber ich konnte nichts genaueres dazu herausfinden. Man sollte wohl davon ausgehen, dass hunderte oder tausende gleichzeitige Anfragen möglich sind.
Ihr könnt ja mal nachsehen, wie viele User und Gruppen eure größten Kunden haben. Wenn die den aktuellen Wrapper einsetzen, werden eventuell simultanceil(groups / 200) + ceil(users / 500)Anfragen auf dem Server aufschlagen.