Prozess und Python Skript für Automatisierung der MP3/Podcast-Veröffentlichung
-
Hallo zusammen
ich bin ein Neuling in Sachen Skripten mit Python, trotzdem möchte ich hier teilen, wie Predigt-MP3 Veröffentlichung dank ChurchTools REST API bei uns semi-automatisch funktioniert, in der Hoffnung, dass entweder der Prozess oder Code(-Teile) für den einen oder anderen hilfreich sein können.
Der Prozess sieht grob wie folgt aus:
- Im Vorfeld wird Serien-Cover im WordPress Modul "Sermon Manager" abgelegt (siehe Spotify Podcast für Beispiele)
- In ChurchTools werden im Vorfeld am Gottesdienst Event der Prediger sowie im Feld "Weitere Info" in definiertem Format Predigttitel (und falls zutrifft Serie) eingetragen: # Predigttitel, bzw. # Serie | Predigttitel
- Die Predigt wird während des Gottesdienstes mit einem Audio-Programm aufgenommen und als MP3 mit Namen JJJJ-MM-TT.mp3 in einem Nextcloud-Ordner abgelegt
- Mithilfe des Skripts wird dann folgendes gemacht:
- Die MP3 wird aus definiertem Nextcloud-Ordner abgeholt und auf Bestätigung erfolgter Bearbeitung abgewartet. Hier erfolgt Zuschnitt vom Audio und Anwendung von Makros in Audacity (Mono, Geräuschentfernung, Export einer neuen MP3 in niedrigerem Bitrate, etc.)
- Nach Bestätigung läuft das Skript weiter und holt für das Datum des MP3 Files die Prediger- und Titel-Informationen aus dem ChurchTools Event
- MP3 Tags werden gesetzt und die Datei entsprechend umbenannt
- Es wird geprüft, ob die Predigt bereits im WordPress veröffentlicht ist. Falls nicht wird die MP3 Datei in einen definierten Import Ordner für die Veröffentlichung auf der Webseite hochgeladen (WordPress Modul Sermon Manager + Sermon Manager Importer)
- YouTube Link zum Gottesdienst-Video wird ermittelt (anhand einer Playlist, um von Info oder Kinder-Gottesdienst-Videos zu unterscheiden)
- Mithilfe von Selenium und chromedriver wird die Predigt importiert (bzw. aktualisiert), indem die URL zum YouTube Video in der Beschreibung hinterlegt wird.
- Im Sermon Manager ist ein Podcast RSS Feed eingestellt, welcher bei Apple Podcast, Spotify Podcast und Google Podcast registriert ist
### install eyed3 and owncloud python modules beforehand # > pip3 install eyed3 # > pip3 install owncloud # > put chromedriver into the directory defined in the cloud_chromedriver_path var below # > put cover.jpg to be used as cover image for mp3 tags # > for help use: python3 <scriptname>.py -h import eyed3 import argparse import sys import os import glob import base64 import json import datetime import time from datetime import date, timezone, timedelta import requests import re import owncloud import ftplib import zipfile from selenium import webdriver from selenium.webdriver.chrome.options import Options from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC ################### Variables ###################### ### ChurchTools global vars ### ct_url = 'https://<MyChurch>.church.tools/api/' # main ChurchTools API URL ct_username = 'churchtools.api@MyChurch.de' # API user name ct_password = 'churchtools.api.Password' # API user password ct_preacher_serviceid = 19 # serviceId of the preacher service in the CT events response (data > eventServices > serviceId) ct_caldomains_bi = [ '2' ] # church branches calender domain ID - (2 = Gottedienste BI) ct_caldomains_gt = [ '24' ] # church branches calender domain ID - (24 = Gottedienste GT) ct_caldomains = [ '2' ] # 2 = Gottesdienste BI, 24 = Gottedienste GT ### Sermon parcing vars ### ct_exclude_titles = [ 'Weitere Infos...', '' ] ct_default_lookback_days = 90 # the greater, the longer it takes. Must be set to the most of passed days since the start of the current sermon series, to insure the correct track number in the album ct_sermon_tag = '#' # sermon tag indicates the beginning of the sermon description within the even description field. e.g.: "Christmas service #The Star of Bethlehem" ct_series_sep = '|' # series separator placed after the series name and before the sermon title. e.g.: "Baptism church service # Following Jesus | The Most Important Decision" ### Cloud vars cloud_url = 'https://cloud.<MyChurch>.de' cloud_username = 'Mp3CloudUser' cloud_password = 'Mp3CloudUserPassword' cloud_download_dirs = [ 'mp3_video_export', 'mp3_audio_mixer' ] cloud_upload_dir = 'mp3_web_import' cloud_local_dir = '/home/<USER>/nextcloud' cloud_chromedriver_path = cloud_local_dir+'/scripts/chromedriver' ### Selenium chromedriver vars driver_url = 'https://chromedriver.storage.googleapis.com/' driver_zip = 'chromedriver_mac64.zip' driver_version_file = cloud_local_dir+'/scripts/CHROMEDRIVER_VERSION' ### FTPs vars ftp_host = '<MyChurch>.de' ftp_username = 'Mp3FtpUser' ftp_password = 'Mp3FtpUserPassword' ### Wordpress vars wp_user = 'Mp3WordPressUser' wp_password = 'Mp3WordPressUserPassword' wp_rest_pass = '1234 abcd 5678 efgh 09jk lmnp' wp_url = 'https://<MyChurch.de/wp-admin/' wp_rest_url = 'https://<MyChurch>.de/wp-json/wp/v2/' wp_sermons = 'edit.php?post_type=wpfc_sermon' wp_url_sermons = wp_url+wp_sermons wp_url_import = wp_url_sermons+'&page=sermon-manager-import' wp_credentials = wp_user+':'+wp_rest_pass wp_token = base64.b64encode(wp_credentials.encode()) wp_header = {'Authorization': 'Basic ' + wp_token.decode('utf-8')} ### Youtube vars yt_url = 'https://www.googleapis.com/youtube/v3/' yt_auth_key = 'RegisterAtGoogleAPIstoGetYourAuthKey' yt_channel_id = 'YourYouTubeChannelID' yt_playlist_id = 'PlaylistIdForChurchServices' yt_max_search_results = '4' yt_max_playlist_results = '10' ### MP3 tag vars mp3_dir = cloud_local_dir+'/put/downloaded/mp3/here' mp3_wdir = mp3_dir+'/mp3/from/audacity/are/found/here' mp3_default_series = 'Einzelne Predigten' # fallback series name mp3_default_preacher = 'Max Mustermann' # preacher name to be used if none is provided mp3_albumartist = 'My Church' mp3_publisher = 'My Church' mp3_composer = 'https://<MyChurch>.de/' mp3_url_apple = 'https://podcasts.apple.com/de/podcast/id000000000000' mp3_genre = 'Podcast' mp3_cover = 'cover.jpg' ################# Functions ####################### def get_args(): parser = argparse.ArgumentParser( description='Arguments for MP3 publishing') parser.add_argument('-f', '--mp3file', type=str, action='store', required=False, help='Use specific local mp3 file instead of making a date guess for the last Sunday and downloading one from the cloud') parser.add_argument('-r', '--remotemp3', default=False, required=False, action='store_true', help='If no owncloud / nextCloud client is installed and the cloud_local_dir is undefined then use this flag to download mp3 from folders defined in cloud_download_dirs') parser.add_argument('-d', '--date', type=str, action='store', required=False, help='Use provided date instead of most recent Sunday') parser.add_argument('-c', '--church', type=str, required=False, default='BI', action='store', help='BI (for Bielefeld) or GT (for Guetersloh)') parser.add_argument('-s', '--single', default=False, required=False, action='store_true', help='Single sermon (not part of series) - works faster!') parser.add_argument('-b', '--lookbackdays', type=int, default=ct_default_lookback_days, required=False, action='store', help='Past days to look back for sermon series. The greater, the longer it takes. Must be set to the most of passed days since the start of the current sermon series, to insure the correct track number in the album. Default: 90') parser.add_argument('-p', '--publish', default=False, required=False, action='store_true', help='Publish the mp3 after tagging') parser.add_argument('-n', '--nextcloud', default=False, required=False, action='store_true', help='Use nextCloud instead of FTP for the MP3 upload. Works only if -p (--publish) is provided') parser.add_argument('-q', '--quiet', default=False, required=False, action='store_true', help='Run the script without user interaction, continue automatically') args = parser.parse_args() return args def get_last_sunday_date(usedate): # check if it's Sunday. If not use last Sunday before this date offset = (usedate.weekday() - 6) % 7 last_sunday_date = usedate - timedelta(days=offset) return last_sunday_date def get_lookback_fromdate(todate, lookback_days): fromdate = todate - datetime.timedelta(days=lookback_days) return fromdate def get_nextday_str(usedate_str): usedate = datetime.datetime.strptime(usedate_str, '%Y-%m-%d') nextday_date = usedate + datetime.timedelta(days=1) return nextday_date.strftime('%Y-%m-%d') def get_nextday_date(usedate): nextday_date = usedate + datetime.timedelta(days=1) return nextday_date def date_to_str(usedate): return usedate.strftime('%Y-%m-%d') def get_valid_title(s): return str(s).replace('...', '…') def get_valid_title_reverse(s): return str(s).replace('…', '...') def get_valid_filename(s): s = str(s).replace('...', '').replace('…', '').replace(':', '.').strip().replace(' ', '_').replace('__', '_').replace(u'Ä', 'Ae').replace(u'Ö', 'Oe').replace(u'Ü', 'Ue').replace(u'ä', 'ae').replace(u'ö', 'oe').replace(u'ü', 'ue').replace(u'ß', 'ss') return re.sub(r'(?u)[^-\w.]', '', s) def build_legacy_filename(date, series, track, title, preacher): date = get_valid_filename(date) series = get_valid_filename(series) track = get_valid_filename(track) title = get_valid_filename(title) preacher = get_valid_filename(preacher) if mp3_default_series in series: filename = date+'_'+title+'_('+preacher+').mp3' else: filename = date+'_'+series+'_['+track+']_'+title+'_('+preacher+').mp3' return filename def build_filename(date, series, title, preacher): date = get_valid_filename(date) series = get_valid_filename(series) title = get_valid_filename(title) preacher = get_valid_filename(preacher) filename = date+'_'+series+'_'+title+'_'+preacher+'.mp3' return filename ### word press selenium login def wp_selenium_logon(d): l = d.find_element_by_xpath("//input[@id='user_login']") if l: l.send_keys(wp_user) d.find_element_by_xpath("//input[@id='user_pass']").send_keys(wp_password) d.find_element_by_xpath("//input[@id='rememberme']").click() d.find_element_by_xpath("//input[@id='wp-submit']").click() ## get a cookie from churchtools def set_ct_cookies(): if 'ct_cookies' not in globals(): login_payload = {'username': ct_username, 'password': ct_password} r = requests.post(ct_url+'login', data=login_payload) global ct_cookies ct_cookies=r.cookies ## split description into series name and sermon title def ct_event_desc_to_sermon(desc): result={} if ct_sermon_tag in desc: sermonline = desc[desc.rfind(ct_sermon_tag)+1:].strip() else: sermonline = desc.strip() if sermonline.count(ct_series_sep) == 1: series = sermonline.split(ct_series_sep)[0].strip() sermon = sermonline.split(ct_series_sep)[1].split('\n')[0].strip() else: series = mp3_default_series sermon = sermonline.split('\n')[0].strip() result['series'] = series.replace('"', '') result['sermon'] = sermon.replace('"', '') return result def get_ct_events(events_from, events_to): set_ct_cookies() events_payload = {'from': events_from, 'to': events_to} r = requests.get(ct_url+'events', cookies=ct_cookies, params=events_payload) r_events = r.json() return r_events['data'] def concat_ct_preacher(event_id): set_ct_cookies() r = requests.get(ct_url+'events/'+str(event_id), cookies=ct_cookies) r_event = r.json() ct_preacher = '' for ct_service in r_event['data']['eventServices']: if ct_service['serviceId'] == ct_preacher_serviceid: ct_preacher = ct_preacher+ct_service['name']+', ' return ct_preacher[:-2] def concat_wp_preacher(wp_preacher_id_list): wp_preacher = '' for wp_preacher_id in (wp_preacher_id_list): r = requests.get(wp_rest_url+'wpfc_preacher/'+str(wp_preacher_id)) wp_preacher = wp_preacher+r.json()['name']+', ' if len(wp_preacher) > 0: return wp_preacher[:-2] else: return '' def concat_wp_series(wp_series_id_list): wp_series = '' for wp_series_id in (wp_series_id_list): r = requests.get(wp_rest_url+'wpfc_sermon_series/'+str(wp_series_id)) wp_series_name = wp_series+r.json()['name'] if wp_series_name[:2].isnumeric() and int(wp_series_name[:2]) >= 7 and int(wp_series_name[:2]) < 45 and wp_series_name[2:5] == ' - ': wp_series_name = wp_series_name[5:] wp_series = wp_series+wp_series_name+', ' if len(wp_series) > 0: return wp_series[:-2] else: return '' ## get all sermon information from an event def ct_event_to_dict(event_data): result = {} event_id = event_data['id'] result[event_id] = {} desc = event_data['description'].strip() s = ct_event_desc_to_sermon(desc) time = event_data['startDate'] result[event_id]['releasedate'] = time[:10] result[event_id]['series'] = s['series'] result[event_id]['sermon'] = s['sermon'] result[event_id]['preacher'] = concat_ct_preacher(event_id) result[event_id]['timeutc'] = time result[event_id]['desc'] = desc result[event_id]['caldomain'] = event_data['calendar']['domainIdentifier'] #result[event_id]['campus'] = event_data['calendar']['domainAttributes']['campusName'] return result def valid_ct_event_to_dict(event_data): if event_data['calendar']['domainIdentifier'] in ct_caldomains and event_data['description'].strip() not in ct_exclude_titles: return ct_event_to_dict(event_data) def cloud_login(cloud_url, cloud_username, cloud_password): cloud = owncloud.Client(cloud_url) cloud.login(cloud_username, cloud_password) return cloud def ftp_login(): global ftp ftp = ftplib.FTP_TLS(ftp_host, ftp_username, ftp_password) ftp.prot_p() return ftp def count_remote_file(ftp): if not ftp: ftp = ftp_login() remote_list = [] ftp.retrlines('LIST', remote_list.append) i = 0 for rf in remote_list: if '.mp3' in rf: i+=1 return i def close_exit(mp3, ftp): mp3.close() ftp.quit() sys.exit() def publish_sermon_ftp(file): ftp = ftp_login() if count_remote_file(ftp) > 0: print("WARNING: The import directory has already mp3 files:") ftp.dir() mp3 = open(file,'rb') print("Uploading '"+file+"' via FTPs to", ftp_host) try: ftp.storbinary('STOR '+file, mp3) except: print("ERROR: '"+file+"' could not be uploaded. Exiting") close_exit(mp3, ftp) print("Upload was successfull") mp3.close() ftp.quit() def publish_sermon_cloud(file): print("Uploading '"+file+"' via nextCloud to", cloud_url, "into the directory '"+cloud_upload_dir+"'") cloud = cloud_login() cloud.put_file(cloud_upload_dir+'/'+file, file) def download_mp3_from_cloud(cloud, remote_file, local_mp3_path, delete_from_cloud_on_ok): print("Downloading '"+remote_file.get_path()+'/'+remote_file.get_name()+"' to '"+local_mp3_path+"'") ok = cloud.get_file(remote_file, local_mp3_path) if ok and delete_from_cloud_on_ok: cloud.delete(remote_file) def get_mp3_from_cloud(cloud_download_dirs, yyyymmdd, delete_from_cloud_on_ok): cloud = cloud_login(cloud_url, cloud_username, cloud_password) local_mp3_path = None for cloud_remote_dir in cloud_download_dirs: # print(cloud_remote_dir) dir_files = cloud.list(cloud_remote_dir) # print(dir_files) for remote_file in dir_files: remote_file_ending = remote_file.get_name()[-4:] # print(remote_file_ending, yyyymmdd, str(remote_file)) if (yyyymmdd == 'all' or yyyymmdd in str(remote_file)) and remote_file_ending == '.mp3': remote_file_name = remote_file.get_name() remote_file_path = cloud_remote_dir+'/'+remote_file_name local_mp3_name = remote_file_name.replace('.mp3', '')+cloud_remote_dir.replace('mp3_', '_')+'.mp3' local_mp3_path = mp3_dir+'/'+local_mp3_name download_mp3_from_cloud(cloud, remote_file, local_mp3_path, delete_from_cloud_on_ok) if remote_file_ending in ['.HM0', '.HMP', '.VIP']: cloud.delete(remote_file) return local_mp3_path def build_youtube_url(yt_video_id): if yt_video_id != None and yt_video_id != '' and len(yt_video_id)>3: return 'https://www.youtube.com/watch?v='+yt_video_id else: return None def get_youtube_playlist_items(): yt_url_playlist = yt_url+'playlistItems?key='+yt_auth_key+'&part=contentDetails&order=date&playlistId='+yt_playlist_id+'&channelId='+yt_channel_id+'&maxResults='+yt_max_playlist_results r = requests.get(yt_url_playlist) return r.json() def get_youtube_playlist_video_id(yt_playlist_items, checkdate): yt_video_id = None for pl_item in yt_playlist_items['items']: if checkdate in pl_item['contentDetails']['videoPublishedAt']: yt_video_id = pl_item['contentDetails']['videoId'] break return yt_video_id def get_youtube_video_id(from_date, to_date): yt_video_id = None yt_search_url = yt_url+'search?key='+yt_auth_key+'&type=video&order=date&channelId='+yt_channel_id+'&maxResults='+yt_max_search_results+'&publishedAfter='+from_date+'T00:00:00Z&publishedBefore='+to_date+'T00:00:00Z' # print(yt_search_url) r = requests.get(yt_search_url) date_videos = r.json() if date_videos['pageInfo']['totalResults'] == 1: for date_video in date_videos['items']: yt_video_id = date_video['id']['videoId'] if yt_video_id == None: yt_playlist_items = get_youtube_playlist_items() for date_video in date_videos['items']: if yt_video_id != None: break else: for pl_item in yt_playlist_items['items']: if yt_video_id != None: break else: if date_video['id']['videoId'] == pl_item['contentDetails']['videoId']: yt_video_id = date_video['id']['videoId'] return yt_video_id def get_youtube_url(from_date, to_date): yt_video_id = get_youtube_video_id(from_date, to_date) if yt_video_id != None: return build_youtube_url(yt_video_id) else: return None def check_wp_sermon_published(sermon_title): found = False r = requests.get(wp_rest_url+'wpfc_sermon') wp_sermons = r.json() for wp_sermon in wp_sermons: if sermon_title == wp_sermon['title']['rendered']: found = True print("The sermon '"+sermon_title+"' is already published.") return found def build_wp_sermon_desc(date_series, date_preacher, youtube_video_url): wp_sermon_desc = '' if (date_series == mp3_default_series or date_series == '' or date_series == None) and date_preacher != None and date_preacher != '' and youtube_video_url == None: wp_sermon_desc = date_preacher elif (date_series == mp3_default_series or date_series == '' or date_series == None) and date_preacher != None and date_preacher != '' and youtube_video_url != None: wp_sermon_desc = date_preacher+" <br />\r\n| <a href=\""+youtube_video_url+"\" rel=\"noopener\" target=\"_blank\">"+youtube_video_url+"</a> |" elif date_series != mp3_default_series and date_series != '' and date_series != None and date_preacher != None and date_preacher != '' and youtube_video_url == None: wp_sermon_desc = date_series+" | "+date_preacher elif date_series != mp3_default_series and date_series != '' and date_series != None and date_preacher != None and date_preacher != '' and youtube_video_url != None: wp_sermon_desc = date_series+" | "+date_preacher+" <br />\r\n| <a href=\""+youtube_video_url+"\" rel=\"noopener\" target=\"_blank\">"+youtube_video_url+"</a> |" else: return wp_sermon_desc def rename_mp3file(mp3file, newfilename): if mp3file != newfilename: print("Renaming '"+mp3file+"' to '"+newfilename+"'") os.rename(mp3file, newfilename) return newfilename def tag_mp3file(mp3file, artist, title, album, year, track_num, release_date): mp3 = eyed3.load(mp3file) if 'NoneType' not in str(type(mp3.tag)): mp3.tag.remove(mp3file) mp3.tag.save() mp3.tag.clear() mp3 = eyed3.load(mp3file) mp3.initTag() mp3.tag.artist = artist mp3.tag.title = title mp3.tag.album = album mp3.tag.year = year mp3.tag.track_num = track_num mp3.tag.release_date = release_date mp3.tag.original_release_date = release_date mp3.tag.recording_date = release_date mp3.tag.tagging_date = release_date mp3.tag.album_artist = mp3_albumartist mp3.tag.genre = mp3_genre mp3.tag.publisher = mp3_publisher mp3.tag.composer = mp3_composer mp3.tag.publisher_url = mp3_composer mp3.tag.internet_radio_url = mp3_url_apple img = open(mp3_cover,'rb').read() mp3.tag.images.set(3, img, 'image/jpeg', mp3_publisher) mp3.tag.save(version=eyed3.id3.ID3_DEFAULT_VERSION, encoding='utf-8') print('Recognized and applied MP3 tags:') print("{}\t{}\t{}\t".format("", "Date: ", mp3.tag.release_date)) print("{}\t{}\t{}\t".format("", "Album: ", mp3.tag.album)) print("{}\t{}\t{}\t".format("", "Track number: ", mp3.tag.track_num)) print("{}\t{}\t{}\t".format("", "Title: ", mp3.tag.title)) print("{}\t{}\t{}\t".format("", "Preacher: ", mp3.tag.artist)) print("{}\t{}\t{}\t".format("", "File name: ", mp3file)) def update_chromedriver(): # get local ver with open(driver_version_file, "r") as f: local_driver_version = f.read().replace("\n", "") # get remote ver r = requests.get(driver_url+'LATEST_RELEASE') remote_driver_version = r.text # compare vers if remote_driver_version > local_driver_version: print("chromedriver will be updated from '"+local_driver_version+"' to '"+remote_driver_version+"'") # move old ver to archive os.rename(cloud_chromedriver_path, cloud_local_dir+'/scripts/archive/chromedriver_'+local_driver_version) # get the new ver zip r = requests.get(driver_url + remote_driver_version + '/' + driver_zip) open(cloud_local_dir+'/scripts/archive/'+driver_zip, 'wb').write(r.content) with zipfile.ZipFile(cloud_local_dir+'/scripts/archive/'+driver_zip, 'r') as zip_ref: zip_ref.extractall(cloud_local_dir+'/scripts') # set permissions os.chmod(cloud_chromedriver_path, 0o775) # set new version as local with open(driver_version_file, "w") as f: f.write(remote_driver_version) def publish_sermon_wp_selenium(mp3file, published, sermon_title, youtube_video_url, description): if youtube_video_url != None: print('Youtube Video URL: '+youtube_video_url) print('Sermon description: '+description) update_chromedriver() global d o = Options() o.add_argument("--disable-infobars") d = webdriver.Chrome(cloud_chromedriver_path, options=o) if not published: ### Open 'Import Sermons' d.get(wp_url_import) d.implicitly_wait(3) wp_selenium_logon(d) d.implicitly_wait(3) ### 'Details' button d.find_element_by_xpath("//button[@id='details-"+mp3file.replace('.', '_')+"']").click() d.implicitly_wait(30) ### import button 'Daten importieren' d.find_element_by_xpath("//input[@name='"+mp3file+"']").click() d.implicitly_wait(10) ### Open 'Alle Predigten' #d.find_element_by_xpath("//a[@href='"+mp3file+"']").click() #d.implicitly_wait(3) d.get(wp_url_sermons) d.implicitly_wait(3) else: ### Open 'Alle Predigten' d.get(wp_url_sermons) d.implicitly_wait(3) wp_selenium_logon(d) ### Open currect sermon for editing d.find_element_by_link_text(sermon_title).click() ### Update embeded youtube video if youtube_video_url != None: v = d.find_element_by_xpath("//input[@id='sermon_video_link']") v.clear() v.send_keys(youtube_video_url) ### Update the description in Sermon Manger Pro #c = d.find_element_by_xpath("//textarea[@name='content']") ### Update the description in Sermon Manager free version c = d.find_element_by_xpath("//textarea[@id='sermon_description']") c.clear() c.send_keys(description) ### Press button 'Aktualisieren' #d.find_element_by_xpath("//input[@id='publish']").click() e = d.find_element_by_xpath("//input[@id='publish']") d.execute_script("arguments[0].click();", e) ### Show updated sermon d.implicitly_wait(3) d.find_element_by_link_text('Predigt ansehen').click() def main(): ###################################################### # SCRIPT BODY ###################################################### args = get_args() if args.mp3file: mp3file_path = args.mp3file mp3file = os.path.basename(args.mp3file_path) usedate = datetime.datetime.strptime(mp3file[:10], '%Y-%m-%d') sermondate = usedate elif args.date: usedate = datetime.datetime.strptime(args.date, '%Y-%m-%d') sermondate = usedate else: usedate = date.today() # check if it's Sunday. If not use last Sunday before this date offset = (usedate.weekday() - 6) % 7 sermondate = usedate - timedelta(days=offset) lookback_days = args.lookbackdays if args.single: lookback_days = 1 fromdate = sermondate - datetime.timedelta(days=lookback_days) # "Monday" after the sermon date nextday = sermondate + datetime.timedelta(days=1) #checktime = sermondate.strftime('%Y-%m-%dT08:00:00Z') checkdate = sermondate.strftime('%Y-%m-%d') lookbackdate = fromdate.strftime('%Y-%m-%d') events_to = nextday.strftime('%Y-%m-%d') if args.quiet: go='y' else: go='' if args.remotemp3: mp3_found = get_mp3_from_cloud(cloud_download_dirs, checkdate, True) if mp3_found == None: sys.exit("No MP3 could be found on the cloud") while go not in ['y', 'n']: go = input("Open Audacity and apply the 'Clean Speech' Macro to the downloaded MP3. Then enter 'y' (yes) to continue or 'n' to stop the script\nShould I continue with tagging? [y/n]: ") if go == 'n': sys.exit("Exiting on user demand") os.chdir(mp3_wdir) mp3_list = glob.glob(str(checkdate)+"*.mp3") if len(mp3_list) > 0: mp3file = mp3_list[0] else: mp3file = mp3_list print("Using '"+mp3file+"' for further processing") if args.church in 'GT': ct_caldomains = ct_caldomains_gt else: ct_caldomains = ct_caldomains_bi ### get event of the sermon for the correct time and church domain/location/campus (Bielefeld vs. Guetersloh) date_releasedate = None date_series = None date_sermon = None date_preacher = None date_events = get_ct_events(checkdate, events_to) for event in date_events: date_event = valid_ct_event_to_dict(event) if date_event != None: for date_event_id in date_event: date_releasedate = date_event[date_event_id]['releasedate'] date_series = date_event[date_event_id]['series'] date_sermon = date_event[date_event_id]['sermon'] date_preacher = date_event[date_event_id]['preacher'] if date_releasedate == '' or date_releasedate == None: date_releasedate = checkdate if date_series == '' or date_series == None: date_series = mp3_default_series if date_sermon == '' or date_sermon == None: date_sermon = input('Sermon title [Predigt vom '+checkdate+']:') if date_sermon == '' or date_sermon == None: date_sermon = 'Predigt vom '+checkdate if date_preacher == '' or date_preacher == None: date_preacher = input('Preacher ['+mp3_default_preacher+']:') if date_preacher == '' or date_preacher == None: date_preacher = mp3_default_preacher # remove chars with different interpretaion in wordpress: date_sermon = get_valid_title(date_sermon) date_series = get_valid_title(date_series) if date_series not in mp3_default_series: event_id = '' allevents = {} events = get_ct_events(lookbackdate, events_to) for event in events: line = valid_ct_event_to_dict(event) if line != None: allevents.update(line) i=0 series_sermons = [] for event in allevents: if allevents[event]['series'] == get_valid_title_reverse(date_series) and allevents[event]['sermon'] not in series_sermons: series_sermons.append(allevents[event]['sermon']) i = len(series_sermons) filename_sermon = date_sermon date_sermon = '('+str(i)+') '+date_sermon date_track_num = str(i) else: date_track_num = date_releasedate[5:7]+date_releasedate[8:10] filename_sermon = date_sermon if 'mp3file' in locals(): mp3file = rename_mp3file(mp3file, build_filename(date_releasedate, date_series, date_sermon, date_preacher)) tag_mp3file(mp3file, date_preacher, date_sermon, date_releasedate[2:4]+' - '+date_series, date_releasedate[:4], date_track_num, date_releasedate) youtube_video_url = get_youtube_url(str(checkdate), str(events_to)) published = check_wp_sermon_published(date_sermon) if args.quiet: go='y' else: go='' while go not in ['y', 'n']: go = input("Should I continue with upload and publishing? [y/n]: ") if go == 'n': sys.exit("Exiting on user demand") if args.publish and not published and not args.nextcloud: publish_sermon_ftp(mp3file) elif args.publish and not published and args.nextcloud: publish_sermon_cloud(mp3file) if args.publish: publish_sermon_wp_selenium(mp3file, published, date_sermon, youtube_video_url, build_wp_sermon_desc(date_series, date_preacher, youtube_video_url)) if __name__ == '__main__': main() -
@andreas-b Interessanter Beitrag vielen Dank.
Da schildere ich mal, wie wir das machen:
-
Veranstaltungen werden in Churchtools gepflegt, und nur dort.
-
im Info-Feld der Veranstaltung stehen Tags mit Meta-Informationen:
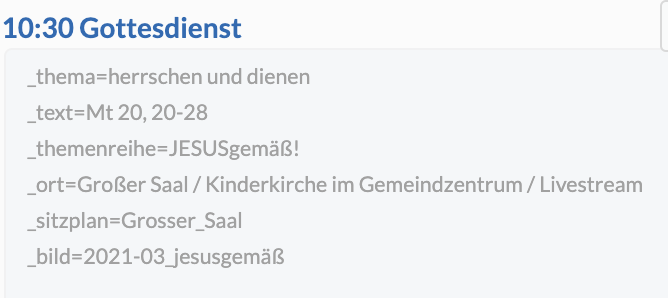
-
Im Ablauf gibt es einen Eintrag "info-fuer-homepage". Dort steht in Markdown der Text, der auf die Homepage soll
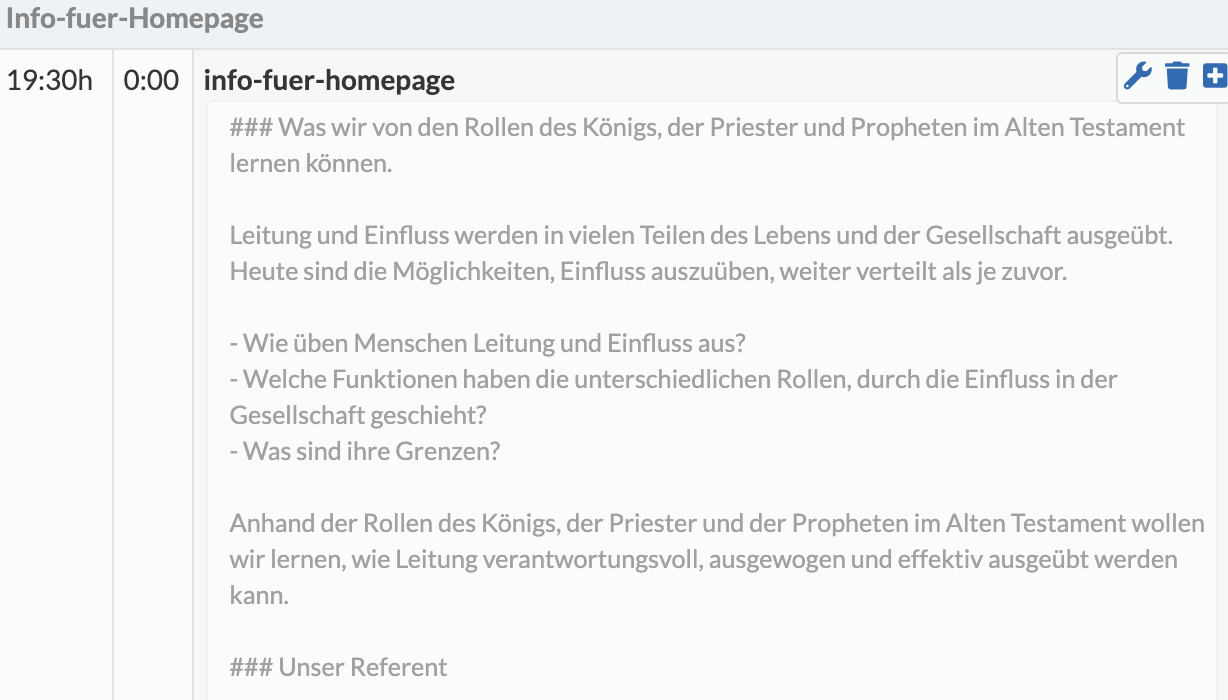
-
Da wir eine gewisse Volatilität in den Details haben, wird einmal pro Stunde CT mit der Homepage synchronisiert (über das API unseres CMS). Dabei werden die "Tags", der Ablauf, und die Dienste von CT sowie der Kalender, verarbeitet. Auch die Steuerung von Livestreameinbettung und Anmeldesystem wird da befüttert.
-
Wir streamen über Twitch. Nach der Veranstaltung schneiden wir ein Highlight und importieren die Links automatisch auf die Homepage.
Um den Technologiestack nicht zu weit zu treiben, läuft das alles mit PHP (obwohl ich lieber Ruby oder sowas hätte).
-
-
@bwl21 sagte in Prozess und Python Skript für Automatisierung der MP3/Podcast-Veröffentlichung:
Am Ende sieht das dann so aus
der Link funktioniert bei mir nicht ...
-
@andy echt jetzt ... bei mir tut das. Was passiert da bei dir?
Der Anmeldelink zu diese Veranstaltung ist abgelaufen, da hab ich schon ein Ticket für.
Probier mal hier, da ist zwar kein Text mehr drin, aber dafür eine Anmeldung
https://www.bruedergemeinde-korntal.de/neuigkeiten/termine/kalender-detail/CT_1995.html
-
@bwl21 jetzt gehen beide. Eben kam "Seite wurde nicht gefunden".